
license: mit
task_categories:
- visual-question-answering
- question-answering
language:
- en
- zh
- ja
pretty_name: Oogiri-GO
size_categories:
- 100K<n<1M
![]()
Oogiri-GO Dataset Card
Project Page | Paper | Code | Model
Data discription: Oogiri-GO is a multimodal and multilingual humor dataset, and contains more than 130,000 Oogiri samples in English (en.jsonl), Chinese (cn.jsonl), and Japanese (jp.jsonl). Notably, in Oogiri-GO, 77.95% of samples are annotated with human preferences, namely the number of likes, indicating the popularity of a response. As illustrated in Fig. 1, Oogiri-GO contains three types of Oogiri games according to the input that can be images, text, or both, and are respectively called "Text to Text" (T2T), "Image to Text" (I2T), and "Image & Text to Text " (IT2T) for brevity.
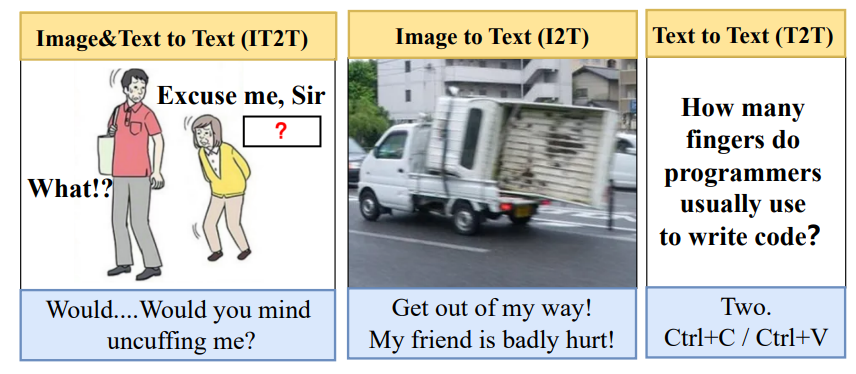 Figure 1. Examples of the three types of LoT-based Oogiri games. Players are required to make surprising and creative humorous responses (blue box) to the given multimodal information e.g., images, text, or both.
Figure 1. Examples of the three types of LoT-based Oogiri games. Players are required to make surprising and creative humorous responses (blue box) to the given multimodal information e.g., images, text, or both.
Each line in the jsonl files represents a sample, formatted as follows:
{"type": "I2T", "question": null, "image": "5651380", "text": "It wasn't on purpose, I'm sorry!", "star": 5}
where type indicates the type of Oogiri game for the sample (T2T, I2T, IT2T); question represents the text question for the sample, with None for types other than T2T; image indicates the image question for the sample, with None for T2T samples; text is the text response for the sample; and star denotes the human preference.
In Japanese data (jp.jsonl) specifically, the questions for T2T type may appear as 'None' because the question text is in image form.
Data distribution: Table summarizes the distribution of these game types. For training purposes, 95% of the samples are randomly selected to construct the training dataset, while the remaining 5% form the test dataset for validation and analysis.
| Category | English | Chinese | Japanese |
|---|---|---|---|
| I2T | 17336 | 32130 | 40278 |
| T2T | 6433 | 15797 | 11842 |
| IT2T | -- | 912 | 9420 |
Project page for more information: https://zhongshsh.github.io/CLoT
License: Creative Commons Attribution 4.0 International. We also adhere to the terms of use from any of the data sources, such as Bokete and Zhihu. If you have any concerns regarding this dataset, especially if you believe it infringes upon your legal rights, please feel free to contact us. We will promptly review any issues raised and respond accordingly.
Citation
@misc{zhong2023clot,
title={Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation},
author={Zhong, Shanshan and Huang, Zhongzhan and Gao, Shanghua and Wen, Weushao and Lin, Liang and Zitnik, Marinka and Zhou, Pan},
journal={arXiv preprint arXiv:2312.02439},
year={2023}
}