
Dataset Viewer
View in Dataset Viewer
Viewer
The dataset viewer is not available for this dataset.
The dataset tries to import a module that is not installed.
Error code: DatasetModuleNotInstalledError
Exception: ImportError
Message: cannot import name 'saveopen' from 'safetensors' (/src/services/worker/.venv/lib/python3.9/site-packages/safetensors/__init__.py)
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/dataset/config_names.py", line 55, in compute_config_names_response
for config in sorted(get_dataset_config_names(path=dataset, token=hf_token))
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 360, in get_dataset_config_names
builder_cls = get_dataset_builder_class(dataset_module, dataset_name=os.path.basename(path))
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 197, in get_dataset_builder_class
builder_cls = import_main_class(dataset_module.module_path)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 115, in import_main_class
module = importlib.import_module(module_path)
File "/usr/local/lib/python3.9/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1030, in _gcd_import
File "<frozen importlib._bootstrap>", line 1007, in _find_and_load
File "<frozen importlib._bootstrap>", line 986, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 680, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 850, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "/tmp/modules-cache/datasets_modules/datasets/OpenDILabCommunity--Pong-v4-expert-MCTS/31ea03218614de6027ebdbb58e94126cc7d31645e64d293cbb2b7e708115933c/Pong-v4-expert-MCTS.py", line 2, in <module>
from safetensors import saveopen
ImportError: cannot import name 'saveopen' from 'safetensors' (/src/services/worker/.venv/lib/python3.9/site-packages/safetensors/__init__.py)Need help to make the dataset viewer work? Open a discussion for direct support.
Dataset Card for Pong-v4-expert-MCTS
Supported Tasks and Baseline
- This dataset supports the training for Procedure Cloning (PC ) algorithm.
- Baselines when sequence length for decision is 0:
Train loss Test Acc Reward 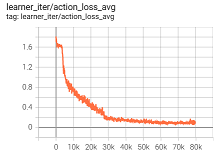
0.90 20 - Baselines when sequence length for decision is 4:
Train action loss Train hidden state loss Train acc (auto-regressive mode) Reward 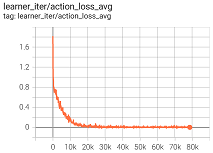


-21




Data Usage
Data description
This dataset includes 8 episodes of pong-v4 environment. The expert policy is EfficientZero, which is able to generate MCTS hidden states. Because of the contained hidden states for each observation, this dataset is suitable for Imitation Learning methods that learn from a sequence like PC.
Data Fields
obs: An Array3D containing observations from 8 trajectories of an evaluated agent. The data type is uint8 and each value is in 0 to 255. The shape of this tensor is [96, 96, 3], that is, the channel dimension in the last dimension.actions: An integer containing actions from 8 trajectories of an evaluated agent. This value is from 0 to 5. Details about this environment can be viewed at Pong - Gym Documentation.hidden_state: An Array3D containing corresponding hidden states generated by EfficientZero, from 8 trajectories of an evaluated agent. The data type is float32.
This is an example for loading the data using iterator:
from safetensors import saveopen
def generate_examples(self, filepath):
data = {}
with safe_open(filepath, framework="pt", device="cpu") as f:
for key in f.keys():
data[key] = f.get_tensor(key)
for idx in range(len(data['obs'])):
yield idx, {
'observation': data['obs'][idx],
'action': data['actions'][idx],
'hidden_state': data['hidden_state'][idx],
}
Data Splits
There is only a training set for this dataset, as evaluation is undertaken by interacting with a simulator.
Initial Data Collection and Normalization
- This dataset is collected by EfficientZero policy.
- The standard for expert data is that each return of 8 episodes is over 20.
- No normalization is previously applied ( i.e. each value of observation is a uint8 scalar in [0, 255] )
Additional Information
Who are the source language producers?
Social Impact of Dataset
- This dataset can be used for Imitation Learning, especially for algorithms that learn from a sequence.
- Very few dataset is open-sourced currently for MCTS based policy.
- This dataset can potentially promote the research for sequence based imitation learning algorithms.
Known Limitations
- This dataset is only used for academic research.
- For any commercial use or other cooperation, please contact: opendilab@pjlab.org.cn
License
This dataset is under Apache License 2.0.
Citation Information
@misc{Pong-v4-expert-MCTS,
title={{Pong-v4-expert-MCTS: OpenDILab} A dataset for Procedure Cloning algorithm using Pong-v4.},
author={Pong-v4-expert-MCTS Contributors},
publisher = {huggingface},
howpublished = {\url{https://huggingface.co/datasets/OpenDILabCommunity/Pong-v4-expert-MCTS}},
year={2023},
}
Contributions
This data is partially based on the following repo, many thanks to their pioneering work:
Please view the doc for anyone who want to contribute to this dataset.
- Downloads last month
- 0