⚗️ 🧑🏼🌾 Let's grow some Domain Specific Datasets together







Communities are made from diverse domains and expertise. We use language models on complex tasks that require expert knowledge. So let's build datasets that reflect this depth and diversity so that we can train and evaluate similarly diverse models!
This is a collaborative project to bootstrap your domain-specific datasets for training models. The goal is to create a share of tools so community users can collaborate with domain experts, and release brand-new datasets.
TL;DR
We’re building domain-specific datasets! You will need one ML engineer and one domain expert. They can be the same person. Go to this space below to get started building your dataset.
Why do we need domain-specific datasets?
LLMs are increasingly used as economical alternatives to human participants across domains like social science, user testing, annotation tasks, and opinion surveys. However, the utility of LLMs in replicating specific human nuances and expertise is limited by training constraints. Models are trained on large-scale datasets that are often biased, incomplete, or unrepresentative of the diverse human experiences they aim to replicate. This problem impacts specific expert domains as well as underrepresented groups in the training data. Furthermore, building synthetic datasets that are representative of the domain can help to improve the performance of models in the domain.
What is the goal of this project?
The goal of this project is to share and collaborate with domain experts to create domain-specific datasets that can be used to train models. We aim to create a set of tools that help users collaborate with domain experts to create datasets that are representative of the domain. We aim to share the datasets openly on the hub and share the tools and skills to build these datasets.
How can I contribute?
🧑🏼🔬 If you are a domain expert, you can contribute by sharing your expertise and collaborating with us to create domain-specific datasets. We're working with users to build applications that help you to define the seed data and create the dataset. We're also working on tools that help you annotate the dataset and improve the quality of the dataset.
🧑🏻🔧 If you are an (inspiring) Machine Learning engineer, you can setup the project and its tools. You can run the synthetic data generation pipelines. And maybe even get around to training models.
How will it work?
I made this walkthrough video of the process from end-to-end. It's around 20 minutes and guides you through some of considerations you may want to make to get usable datasets:

1. Select a domain and find collaborators
We start by selecting a domain and finding collaborators who can help us to create the dataset.
🧑🏼🔬 If you are a domain expert, you could find an ML engineer to help you to create the dataset.
🧑🏻🔧 If you are an ML engineer, you could find a domain expert to help you to create the dataset.
🧑🚀 If you're both, you could start by defining the seed data and creating the dataset.
2. Setup your project
First, you need to set up the project and its tools. For this, we use this application
3. Define the domain knowledge
Next, we need to get the domain expert to define the seed data. This is the data that is used to create the dataset. Once the seed data is defined, we add it to the dataset repo.
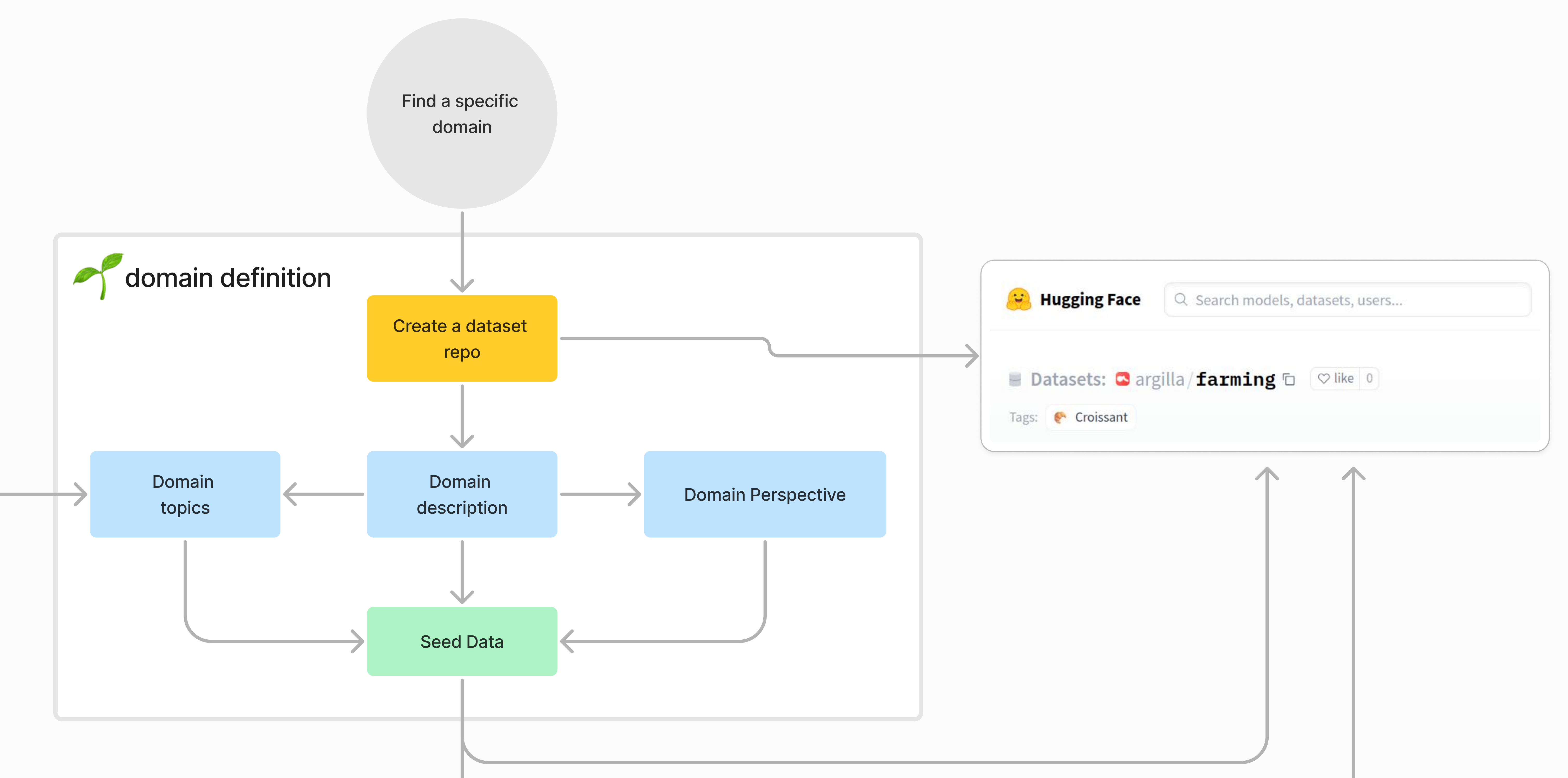
Domain topics are the topics that the domain expert wants to include in the dataset. For example, if the domain is farming, the domain topics could be "soil", "crops", "weather", etc.
Domain description is a description of the domain. For example, if the domain is farming, the domain description could be "Farming is the practice of cultivating crops and livestock for food, fiber, biofuel, medicinal plants, and other products used to sustain and enhance human life."
Domain perspectives are the perspectives that the domain expert wants to include in the dataset. For example, if the domain is farming, the domain perspectives could be "farmer", "agricultural scientist", "agricultural economist", etc.
4. Generate the dataset with distilabel
Next, we can move on to generating the dataset from the seed data.
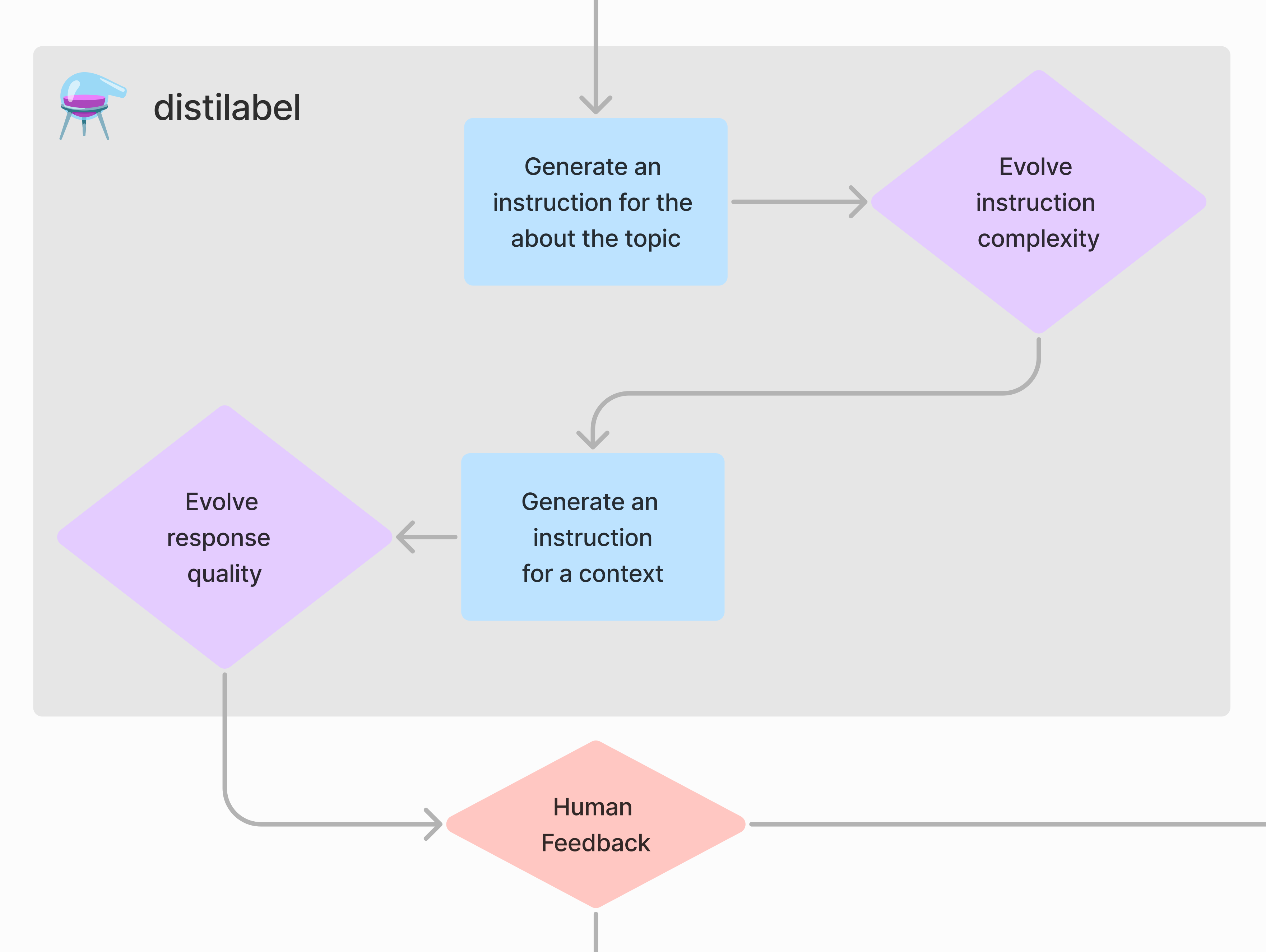
- The pipeline takes the topic and perspective and generates instructions for the dataset, then the instructions are evolved by an LLM to create more instructions.
- The pipeline takes the instructions and generates responses for the dataset, then the responses are evolved by an LLM to create higher-quality responses.
5. Review and share the dataset
Finally, the pipeline pushes the dataset to the hub and Argilla space. The domain expert can then review the dataset by annotating the dataset and improving the quality of the dataset. Once finished, the ML engineer can push the dataset to the Hub.
🧑🚀 Let’s Start!
To start your project go to this space. Instructions are repeated throughout the app.





