
This could likely be dewokefied and possible even improved using mergekit's new 'Model Stock' method!

WizardLM-2-8x22B, mixtral-8x22b-instruct-oh and Tess-2.0-Mixtral-8x22B all use the same prompt format.
So mergekit's 'Model Stock' algorithm should work (along with the base Mixtral-8x22B-v0.1) to hopefully create an instruction-following version of Mixtral-8x22B without all the woke stuff baked in from WizardLM-2-8x22B and likely a lower perplexity than any of the fine-tuned models alone.
My poor internet is getting crushed by all these massive model drops, but this is what the mergekit.yaml file would be:
models:
- model: mistral-community/Mixtral-8x22B-v0.1
- model: alpindale/WizardLM-2-8x22B
- model: fireworks-ai/mixtral-8x22b-instruct-oh
- model: migtissera/Tess-2.0-Mixtral-8x22B
base_model: mistral-community/Mixtral-8x22B-v0.1
merge_method: model_stock
dtype: float16
I can't find any other Mixtral-8x22B-v0.1 fine-tunes using this prompt format, but you probably don't need them as I've used the 'Model Stock' method quite successfully with just base and 2 x fine-tuned versions (ie: the minimum for this method to work).
See: https://arxiv.org/abs/2403.19522
It is very different to just blending the weights together (which the paper shows doesn't actually improve the models):
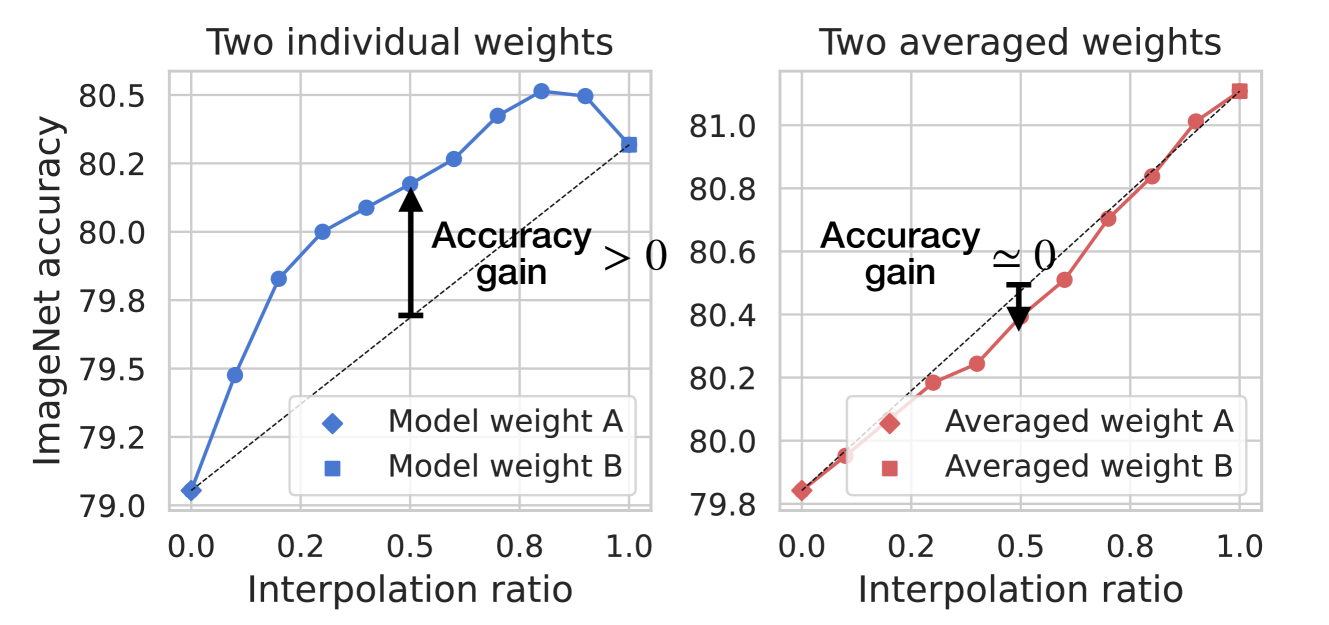
It essentially tries to make a model that would be the limit of a large number of models averaged together, and from experiments so far it does actually reduce the perplexity below any of the donor fine-tunes.

EDIT: Just double checked and MixtralForCausalLM is an option inside of mergekit/architecture.py and since it seems 8x22B is just a scaled up version of 8x7B that works in most stuff without any changes, it should work fine!

this is interesting, but what if the other fine-tuned models are also censored or aligned with a specific view? I assume we do need other models to have some sense of NSFW, right?
this is interesting, but what if the other fine-tuned models are also censored or aligned with a specific view? I assume we do need other models to have some sense of NSFW, right?
Yeah, but I think the other two models are just very light fine-tunes to try to get the base model to follow instructions.
This method definitely doesn't work for continued-pretrained models (eg: no way you could use miqu-1 and codellama-70b-hf on top of llama2 base) so models from groups with vastly unbalanced resources may not work that well either, but it is definitely worth trying.
Just interpolating WizardLM-2-8x22B back towards Mixtral-8x22B-v0.1 will likely get rid of some censoring (as it's effectively the same as using Mixtral-8x22B-v0.1 weights as a prior / as a form of L2-regularization), but at the risk of ruining the instruction-following (I've tried this before 'model stock' was added to mergekit and it didn't work very well / at all).
I found this method works quite well for coding models that have the same prompt format and RoPE settings - in fact it's the only method that does anything but ruin coding models from all my tests so far; and is especially effective when a group releases a paper where they compare/upload multiple different fine-tuned versions.
I'm also not sure how important the prompts being the same are as have always tried to avoid mixed prompts so far.
It will be at least 2 more days before I can get mixtral-8x22b-instruct-oh and Tess-2.0-Mixtral-8x22B to try this (just getting Mixtral-8x22B-v0.1 now and got WizardLM-2-8x22B last night), and even then there will be absolutely no way I can upload a merged model of ~260GB at 1MB/s so it would be best if somebody else could try this if they have these models already downloaded over the last few days...
I do have 2 fine-tuned models based on Mixtral-8x22B, would love to try model_stock and see what happens in the end. Please do share your progress, seems very interesting.

I will download these three models and merge them as @jukofyork mentioned. I should have them ready by tomorrow and will upload them by tomorrow. I will also quantize them if needed. Could someone point out what are the best quantization methods and what should I use to create those? I got three 4090s in a rig and 128GB or ram. I can merge them overnight, in the next few days. I tried quantization in the past, but always sus on whether I did it well or not. Could someone kindly tell me what would be the best config be for these models and I promise to upload them ASAP.

Could someone kindly tell me what would be the best config be for these models and I promise to upload them ASAP.
Exl2 is the best as far as I know. ExllamaV2 also supports 4-bit cache which means you can fit higher quality quant with the same context length. I did not yet try 8x22B (my internet connection is not very fast) but I think for triple 24GB card 3.5bpw would be the best fit. This is the quant which I would like to try too, so it could be great if you can create it. This is how to create Exl2 quant: https://www.reddit.com/r/LocalLLaMA/comments/1aybeji/exl2_quantization_for_dummies/ - there is a comment there that explains the process in just a few short steps, here is the link to it: https://www.reddit.com/r/LocalLLaMA/comments/1aybeji/comment/krvjvcq/
Probably a good idea to have 3.0, 3.25, 3.5, 3.75, 4.0 and 5.0bpw quants if you have resources to generate more than one, so it would be possible to choose from depending on amount of available VRAM and required context length. For the first upload, 3.5bpw would be great though, and it should work well on your 3x4090 rig too (please note that since I did not try it myself, it is just a guess). As an example, here are quants turboderp released for the base 8x22B model: https://huggingface.co/turboderp/Mixtral-8x22B-v0.1-exl2 in case you are curious what bpw are usually worth making.
In my experience, quants below 3.0bpw drop in quality too much, so it may be worth creating GGUF quant for people with limited VRAM instead. I would be happy to generate quants myself, but with my internet speed it would take very long to download all required models to even try (about a week or two, and then it would practically impossible for me to share the result, since with my upload speed it would take few weeks to upload).
Having at least one 4.0 GGUF quant for people with less than 72GB VRAM but sufficient RAM could useful as well. But compared to EXL2, GGUF is slower and consumes more VRAM, since it does not support 4-bit cache. I generally try to avoid using GGUF, if I can fit EXL2 version at acceptable bpw to VRAM.
Thanks a ton buddy! I am working right now (day job) and have made it one of my tasks for the end of the day. I will quantize it and maybe even create the model and upload it late evening (German time) today. I have a 1000Mbps connection at work download and upload, so it should be fast enough for uploads. For the work PC I only have a single 3090ti and 128GB RAM, I am a data scientist and train a lot of models. I was also thinking of merging the three models - 8x22b base, 8x22b zephyr and the wizardlm2 as well as i saw that many people are having issues with the wizardlm2. Check my profile and as I promised, I will be uploading even if I have to skip a few things in the evening. I will keep you updated. Check my profile as I will be uploading there.
On a second thought, I think I should upload the quants for command r+ model as well, maybe even some merged models. Could someone point to me to some models finetuned on cohere r+, so I can possibly merge them?
Having at least one 4.0 GGUF quant for people with less than 72GB VRAM but sufficient RAM could useful as well.
If you had any issue doing GGUF I can help :)
Could you please share some GGUF quant docs so that I can go through them and then quantize all the required models and upload them? Some sample recipes would be good as well. Your help would be amazing :)
This is a great to start: https://github.com/ggerganov/llama.cpp/discussions/2948
I follow these steps to first convert to GGUF 16bit, and then based on that do the quants (it would be a better quality to go from the 16bit to others)
Look what just dropped: https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1
(and https://huggingface.co/mistralai/Mixtral-8x22B-v0.1)
I think my ISP is gonna disown me soon... :D
I wouldn't waste much time trying to use the model_stock thing until we see what the official instruct release is like!
I have nearly downloaded it. Will quantize it and then upload. After that merging three - base, wizardlm2 and mixtral instruct and then uploading the f16 and then quantized upload. First gguf q4_k_s as this is the first one on my list and then later on. I got 1000Mbps. Give me a list of models for merging if needed.
I have nearly downloaded it. Will quantize it and then upload. After that merging three - base, wizardlm2 and mixtral instruct and then uploading the f16 and then quantized upload. First gguf q4_k_s as this is the first one on my list and then later on. I got 1000Mbps. Give me a list of models for merging if needed.
Yeah, that would definitely be interesting to try merging: base, wizardlm2 and mixtral-instruct using the model_stock method!
But they have different tokenizers tho. Mistral literally made a new repo for this to tokenize the text differently... would there be no issue when merging? I mean the wizardlm2 uses vicuna while mixtral instruct uses the typical mistral chat format
But they have different tokenizers tho. Mistral literally made a new repo for this to tokenize the text differently... would there be no issue when merging? I mean the wizardlm2 uses vicuna while mixtral instruct uses the typical mistral chat format
Ah yeah, you are right. I think mergekit can somewhat deal with very slightly different tokenizers but the different prompt template is likely to be a no go.
There are a few fine-tunes using the [INST] {prompt} [/INST] template too:
https://huggingface.co/openbmb/Eurux-8x22b-nca
https://huggingface.co/openbmb/Eurux-8x22b-kto
https://huggingface.co/tdrussell/Mixtral-8x22B-Capyboros-v1
Looks like
@Undi95
has also been using the new model_stock method for dewokefication:
https://huggingface.co/Undi95/Miqu-MS-70B
and seems to mix together 3 different prompt formats too!? I wonder if this works OK or if it start to randomly pop out with "### Instruction:" or "USER:" mid conversation?
I have tried this and the model goes off the rails. Quite badly! We would need to finetune it further, albeit not much but still would have to.
I have tried this and the model goes off the rails. Quite badly! We would need to finetune it further, albeit not much but still would have to.
Do you mean you tried a mixed prompt merge or it even went off the rails for models using the same prompt?
I've got the two euruxmodels downloaded back home and was going to try this using them and the official mixtral-instructwhen I get back.
I actually did mixed prompt as I wanted to mix in a few models who are allegedly very good on the benchmarks. But after I did that, the models did go off- the rails.
Another thing that I tried was using two totally different models, with the same tokenizer, to predict the next token. Here I utilized max log prob for the next token for each model and fed that recursively until I hit the end token. The idea worked and I had a model that was extremely good at coding and maths. I asked it to solve CFA level 2 problems and it worked. So like a mixture of experts but independent models. The final "model" was very modular and you could switch models with whatever you wanted, given that the relative tokenizers are the same. But this goes off the rails, when you use models with different tokenizers and can cause massive issues.
I think we should try making the llama-3 models bigger and then finetune them to follow instructions. I saw some reports and posts from ehartfort that this can indeed make the model access its knowledge better than it did when it was smaller. I think self merging also does not require even finetuning sometimes as the prompt just works! Should we have a discord to discuss these ideas? I am down for it. I am a data scientist and I want to learn more about all these techniques even more. It would be cool if some people joined so I can discuss with them regularly?
I actually did mixed prompt as I wanted to mix in a few models who are allegedly very good on the benchmarks. But after I did that, the models did go off- the rails.
Yeah, all my attempts at mixing prompt templates or merging back in a fraction of the base model (as a "quick and dirty" attempt at regularisation) have failed too.
Another thing that I tried was using two totally different models, with the same tokenizer, to predict the next token. Here I utilized max log prob for the next token for each model and fed that recursively until I hit the end token. The idea worked and I had a model that was extremely good at coding and maths. I asked it to solve CFA level 2 problems and it worked. So like a mixture of experts but independent models. The final "model" was very modular and you could switch models with whatever you wanted, given that the relative tokenizers are the same. But this goes off the rails, when you use models with different tokenizers and can cause massive issues.
This is called "late fusion" - usually you sum the logits (pre-softmax) or equivalently; take the geometric mean of the categorical distribution (post-softmax). Then you can use greedy (or any other form of) sampling in the same way as you would with one model.
I've been trying to get the Mergekit people interested in this as I think ensembling like this has the potential to work very well and is well understood in terms of reducing variance, etc.
I even think different tokenizers could be ensemble like this by sampling multiple tokens into the future and finding the points where the paths cross, etc. The tokenizers aren't all that different if you allow combinations of 2-3 tokens. I actually have a lot of experience writing things like this: if you have ever played online poker and have seen the "adjusted EV" graphs that smooth out all-in luck, then I was the first person to implement that around ~15 years ago.
Different prompt templates wouldn't be a problem either, as you could format it different for each model and for all by the most oddball templates this would work fine and each model would just see the context text in the format it wants.
I'm also fairly sure I know why Beam Search is working so badly for LLMs:
- When people first started trying to roll the tree of player actions into the future for poker, they initially tried to just (greedily) expand the top few actions with the highest probabilities (to try to avoid a combinatoral explosion in the branching factor).
- It turns out if you do this then you get a biased estimate of the EV when you back up the probabilities because the actions with the highest probability were using "fold, fold, fold, ..." sequences.
- The solution was pretty simple: probabilistic expansion of the nodes based on the action probability (this was a couple of years before MCTS was discovered).
I'm not sure how feasible it is to do this for LLMs as they are so expensive to sample from autoregressivly , but it's possible some clever form of batching could be used to do this. Looking at ways of rolling the KV-cache back and forth would be important too.
I think we should try making the llama-3 models bigger and then finetune them to follow instructions. I saw some reports and posts from ehartfort that this can indeed make the model access its knowledge better than it did when it was smaller. I think self merging also does not require even finetuning sometimes as the prompt just works! Should we have a discord to discuss these ideas? I am down for it. I am a data scientist and I want to learn more about all these techniques even more. It would be cool if some people joined so I can discuss with them regularly?
I'm interested but only for fun. I love fiddling about with things like this, but I have no real interest/need to take it seriously nor care to publish anything.
I do have a degree in CS (actually CS "with AI" - there was no such thing as ML or data science in the 90s!), but I really don't like Python and would only use it for the absolutely minimum interface code or when absolutely the only option... The idea of writing anything serious in Python is a complete no go for me.
I've been trying to get the Mergekit people interested in this as I think ensembling like this has the potential to work very well and is well understood in terms of reducing variance, etc.
For this I think you could open a pr and maybe they someday merge it. I could also add some comments or something to get some traction going. I think combining models trained from multiple companies could lead to better models, as the companies are not declaring what exact data that they are using. And as we are seeing it more and more as time passes, that the quality of data is the other end of spectrum where given constrained compute quality can make a huge difference. And there is also the diversity of training factor, where combined with enough models, we could have a good distribution to sample from. Law of large numbers.
I even think different tokenizers could be ensemble like this by sampling multiple tokens into the future and finding the points where the paths cross, etc. The tokenizers aren't all that different if you allow combinations of 2-3 tokens. I actually have a lot of experience writing things like this: if you have ever played online poker and have seen the "adjusted EV" graphs that smooth out all-in luck, then I was the first person to implement that around ~15 years ago.
Very interesting. It makes sense, intuitively. I mean if you cover a word, e.g or then predicting the next thing should not be that much dependent on the different tokenizers. But yeah, need to combine 2-3, 3-4 tokens together. I will do some ablation study on it, to see where the quality of the model drops and the quality of the output drops.
Different prompt templates wouldn't be a problem either, as you could format it different for each model and for all by the most oddball templates this would work fine and each model would just see the context text in the format it wants.
I meant that merging models with different template does not work. Using ensemble with different model works for sure. I tested it.
I combined two different size models - one optimized for maths and the other one for code, and by God, the results were very fascinating. I made the outputs to be in different colors to see where which model switches, based on model level confidence. I also implement various temperatures - ablation, one global temperature and two temperatures for each of the constituent models. And you could see that the switching back and forth. Like actual mixture of experts. I would dare to call it mixture of experts rather than ensemble as the specific models are different for each task.
I'm also fairly sure I know why Beam Search is working so badly for LLMs:
When people first started trying to roll the tree of player actions into the future for poker, they initially tried to just (greedily) expand the top few actions with the highest probabilities (to try to avoid a combinatoral explosion in the branching factor).
It turns out if you do this then you get a biased estimate of the EV when you back up the probabilities because the actions with the highest probability were using "fold, fold, fold, ..." sequences.
The solution was pretty simple: probabilistic expansion of the nodes based on the action probability (this was a couple of years before MCTS was discovered).
Sorry this went over my head haha. Could you be kind enough to link some stuff here so I can read more about this? Also some sources on efficient poker games...
I'm interested but only for fun. I love fiddling about with things like this, but I have no real interest/need to take it seriously nor care to publish anything.
I do not even have a degree in CS. I did a lot of Andrew Ng courses. He is my actual guru and youtube MIT opencourseware haha. I am a mechanical engineer in bachelors and Business Analytics by masters. I was a good programmer, but never took it "officially". I work on a lot of side projects, probably too many. I do research for my job as a data scientist in a finance and management university using ML, like writing papers and stuff. So, for a hobby and experimentation and projects, I am definitely not looking to write papers haha. It was more of a gathering to get ideas from people with diverse thought processes. Let me know if you still want to buddy. I want to learn a lot. I am 27, but just getting started haha. Learning and making stuff is my hobby. And I work in python majorly. I did a lot of C, C++ in my high school and bachelors, but am very rusty on it.
Cheers!
I have another question. When I use gguf models, can I somehow change the template? I set up llama.cpp server locally, but apparently it uses some chat template precooked it. Can I somehow remove it and just use the template which I can make using the huggingface tokenizer and then just sent it that text? As in llama.cpp models, there is a message hi and how can i help you attached in the prompt template and that messes up with my code and responses when I want a json or a specific prompt as it is already proded to have a chat conversation. This has gotten so annoying that I wrote a json extractor to get the json out of the text. I would highly appreciate it!
I have another question. When I use gguf models, can I somehow change the template? I set up llama.cpp server locally, but apparently it uses some chat template precooked it. Can I somehow remove it and just use the template which I can make using the huggingface tokenizer and then just sent it that text? As in llama.cpp models, there is a message hi and how can i help you attached in the prompt template and that messes up with my code and responses when I want a json or a specific prompt as it is already proded to have a chat conversation. This has gotten so annoying that I wrote a json extractor to get the json out of the text. I would highly appreciate it!
https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template
It seems ggerganov is very reluctant to use Jinja2C++ as it uses Boost and all the C++ templates slow the compile times right down.
I've been using Ollama as it wraps the llama.cpp server and lets you use Go's text/template syntax in their modelfiles. Ollama is bit buggy though and they don't make it easy to see the diagnostic output... I'm never 100% sure if what I think is getting passed on is actually what I think it is.
The other option is just to use the completion API endpoint and manually code up the template formatting yourself - at least then you know for sure what is getting passed, but it's a lot of hassle to do for every new model that you try.
I have been using the completion API from openai as that is I guess what you mean. But I notice that even though I give it a system prompt for just json, I get conversational responses like, here is the output that you requested. Is there a way to somehow, remove this "default" template that the model is using. because whenever I load the model, I can see that this template is loaded in there. This is getting very annoying as the model always gives me an affirmation however much I beg it not to haha. The command that I use is:
./server -m model_path -a "alias" -c 8192 -mg 0 -ts "2,3,3" -ngl 81 -cb -np 4
As you can see I am not supplying any chat template, but this does load a chat template on its own which has messages such as :
{"tid":"135090017931264","timestamp":1713871273,"level":"ERR","function":"main","line":3028,"msg":"The chat template that comes with this model is not yet supported, falling back to chatml. This may cause the model to output suboptimal responses"}
{"tid":"135090017931264","timestamp":1713871273,"level":"INFO","function":"main","line":3043,"msg":"chat template","chat_example":"<|im_start|>system\nYou are a helpful assistant<|im_end|>\n<|im_start|>user\nHello<|im_end|>\n<|im_start|>assistant\nHi there<|im_end|>\n<|im_start|>user\nHow are you?<|im_end|>\n<|im_start|>assistant\n","built_in":false}
This is hella annoying. Is there way to just remove this bs totally and I just send the prompts with the appropriate template that I wish for.
I meant that merging models with different template does not work. Using ensemble with different model works for sure. I tested it.
Sorry, huggingface went down right after I made this post and I didn't get time reread or edit it:
This was specifically about "late fusion": running two completely separate models but then summing the logits pre-softmax (ie: ensembling rather than merging).
For the same tokenizers, but different prompt templates:
- Using the completions API pass the models the string "Hi, what is your name?" like this:
<s>[INST] Hi, what is your name? [/INST]
<s>### Instruction:
Hi, what is your name?
### Response:
<s>USER: Hi, what is your name? ASSISTANT:
- Ask them to generate the next token and return their pre-softmax logits or (their post-softmax categorical distribution).
- Then combine as I mentioned above using sum of pre-softmax logits (or geometric mean of post-softmax probabilities).
- Sample from this new combined distribution.
Let's say the next token was " My":
- We can update like so:
<s>[INST] Hi, what is your name? [/INST] My
<s>### Instruction:
Hi, what is your name?
### Response:
My
<|BOS|>USER: Hi, what is your name? ASSISTANT: My
and carry on until we sample the EOS token and then add that:
<s>[INST] Hi, what is your name? [/INST] My Name Is Legion<\s>
<s>### Instruction:
Hi, what is your name?
### Response:
My Name Is Legion<\s>
<|BOS|>USER: Hi, what is your name? ASSISTANT: My Name Is Legion<|EOS|>
and so on for the next round of conversation.
The different prompt formats won't make any different here as each model will be "seeing" the context/generated text in the format they expect. The only time there might be problems is some of the really oddball prompt templates that use special tokens for RAG or FIM, etc.
Sorry this went over my head haha. Could you be kind enough to link some stuff here so I can read more about this? Also some sources on efficient poker games...
Sadly these posts are really hard to find as the TwoPlusTwo forums moved over to use new form software around 2008 and archived all the old posts with semi-broken search (if it even still works).
The basic idea is this:
For games with an element of chance (eg: backgammon) and/or with hidden information (eg: poker) you have to use an algorithm called Expectiminimax rather than Minimax which is used for fully observable deterministic games (eg: chess).
So to get the evaluations at each node you need to sample paths into the future that hit a state where you get a result (eg: the end of a poker hand where the pot gets divided up) and then average these to get the expected value of taking an action (eg: fold = -$2, raise = +3, call = $1 [on average]).
People now use Monte Carlo Tree Search to balance the "Exploration and Exploitation" aspect, but until the mid to late 2000s nobody really knew about this and were just trying whatever they could to extend the poker hand calculations into the future to avoid the Horizon Problem.
Well since these trees blow up massively in multiplayer games, the first idea they had was to just greedily sample the most probable action in each node. This is similar to using Beam Search or Monte Carlo Tree Search without any actual exploration...
Interestingly the first software to try this had "Wizard" in the name and tried to use the Independent Chip Model in Sit-and-go tournaments where the Horizon Problem was particularly punishing, eg:
Imagine 4 players, 3 get paid, you get dealt AA and have the second smallest stack of chips, but the next hand you can see a player with 0.1 blinds worth of chips has to pay both the small blind and the big blind.
If you don't look into the future it will look like going all-in is optimal, but in most cased fact you should fold and the the player hit both the blinds and likely go out before you!
This did work to some extent but it soon became clear there was a big problem with greedy sampling as the most likely string of actions after you was nearly always "fold, fold, fold, fold, ..." and so on.
So the expected values you were propagating back up to the node to make a decision were completely off and were effectively a Biased Estimator of the true EV!
The solution was actually fairly simple: don't sample greedily but sample based off the probability of an action instead. This means the most probably fold actions get sampled more often, but also the rarer call/raise actions also get sampled sometimes too... When the expected values now get backed up to the decision node the expected values are now much closer to what would happen if you were to actually play out infitly many versions of the same hand and much less biased.
We now have a much better understanding of this via Monte Carlo Tree Search, but back then this was pretty important as just a tiny edge over other players like this could help you learn to beat other players by using the "Wizard" whatever it was called software to study your previous hands and plug leaks...
So hopefully it's clear why just sampling from LLMs using greedy Beam Search is likely to also lead to biased estimates of the actual rolled out multi-token sequences, and the problems people report of them going round in loops or producing sub-optimal sentences is likely a manifestation of the very same problem.
I've no idea how easily it would be to implement this efficiently in LLMs currently (you would need to be able to roll the KV-cache back and forth), but it's likely an interesting avenue to explore at some point if computationally infeasible currently.
I have to go out for the afternoon, but will explain the outline of how we can (in theory) combine the probabilities of multi-token sequences of different tokenizers using a tree when I get back.
Is there a way to somehow, remove this "default" template that the model is using. because whenever I load the model, I can see that this template is loaded in there. This is getting very annoying
Look in the llama.cpp/gguf-py/scripts folder for the gguf-set-metadata.py tool.
You can use this to remove the template from the gguf header (I think).
Or alternatively you can remove it from the HF dcownload in tokenizer_config.json and then convert to gguf yourself.
(sorry really have to go).
Thanks a lot @jukofyork . I really appreciate you taking the time to explain all of this in such great detail. Even though you are that busy with life, you took the time to respond in great detail, makes me grateful. I am trying the gguf-set-metadata.py changes today and hope to see it work. Otherwise I just downloaded the raw models anyways and will remove the chat template and send custom strings to it later on.
The appended messages such as "Hi" and "Hi there!" mess up the generations for me as then it becomes very chat based onad does not generate instructions that well.
Could you please recommend some good tool calling library as well? I am hand coding all the llm calls, parsing and stuff but it gets annoying when switching models back and forth, but could you please tell me if there is something that is out there that I can directly use with the llama.cpp backend? Also is there some UI that I could use to see the tool in action. It is soo much stuff out there that getting the signal is so difficult.
If someone else knows, help me. @MaziyarPanahi