















Post
1284
🔍 Today's (self-serving) pick in Interpretability & Analysis of LMs:
A Primer on the Inner Workings of Transformer-based Language Models
by @javifer @gsarti @arianna-bis and M. R. Costa-jussà
( @mt-upc , @GroNLP , @facebook )
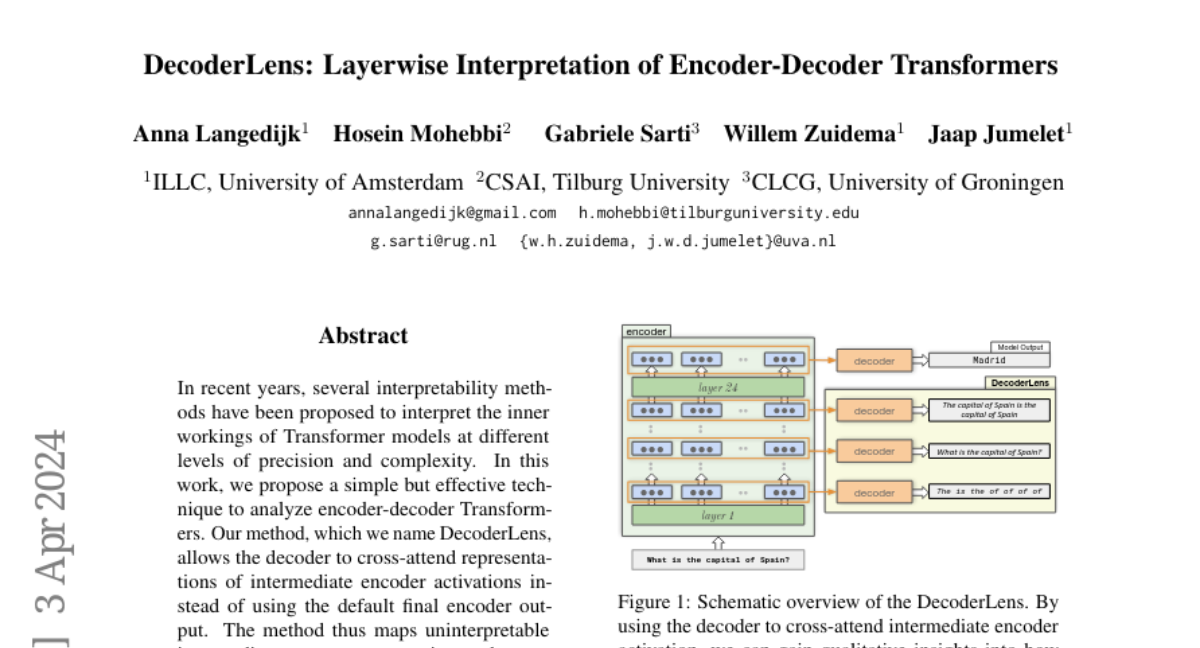
This primer can serve as a comprehensive introduction to recent advances in interpretability for Transformer-based LMs for a technical audience, employing a unified notation to introduce network modules and present state-of-the-art interpretability methods.
Interpretability methods are presented with detailed formulations and categorized as either localizing the inputs or model components responsible for a particular prediction or decoding information stored in learned representations. Then, various insights on the role of specific model components are summarized alongside recent work using model internals to direct editing and mitigate hallucinations.
Finally, the paper provides a detailed picture of the open-source interpretability tools landscape, supporting the need for open-access models to advance interpretability research.
📄 Paper: A Primer on the Inner Workings of Transformer-based Language Models (2405.00208)
🔍 All daily picks: https://huggingface.co/collections/gsarti/daily-picks-in-interpretability-and-analysis-ofc-lms-65ae3339949c5675d25de2f9
A Primer on the Inner Workings of Transformer-based Language Models
by @javifer @gsarti @arianna-bis and M. R. Costa-jussà
( @mt-upc , @GroNLP , @facebook )
This primer can serve as a comprehensive introduction to recent advances in interpretability for Transformer-based LMs for a technical audience, employing a unified notation to introduce network modules and present state-of-the-art interpretability methods.
Interpretability methods are presented with detailed formulations and categorized as either localizing the inputs or model components responsible for a particular prediction or decoding information stored in learned representations. Then, various insights on the role of specific model components are summarized alongside recent work using model internals to direct editing and mitigate hallucinations.
Finally, the paper provides a detailed picture of the open-source interpretability tools landscape, supporting the need for open-access models to advance interpretability research.
📄 Paper: A Primer on the Inner Workings of Transformer-based Language Models (2405.00208)
🔍 All daily picks: https://huggingface.co/collections/gsarti/daily-picks-in-interpretability-and-analysis-ofc-lms-65ae3339949c5675d25de2f9