Text Embeddings Inference
Text Embeddings Inference (TEI) is a comprehensive toolkit designed for efficient deployment and serving of open source text embeddings models. It enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE, and E5.
TEI offers multiple features tailored to optimize the deployment process and enhance overall performance.
Key Features:
- Streamlined Deployment: TEI eliminates the need for a model graph compilation step for an easier deployment process.
- Efficient Resource Utilization: Benefit from small Docker images and rapid boot times, allowing for true serverless capabilities.
- Dynamic Batching: TEI incorporates token-based dynamic batching thus optimizing resource utilization during inference.
- Optimized Inference: TEI leverages Flash Attention, Candle, and cuBLASLt by using optimized transformers code for inference.
- Safetensors weight loading: TEI loads Safetensors weights for faster boot times.
- Production-Ready: TEI supports distributed tracing through Open Telemetry and exports Prometheus metrics.
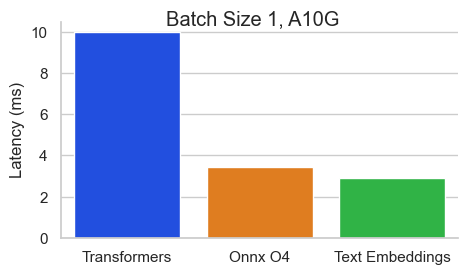
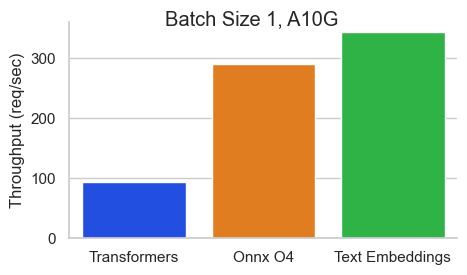
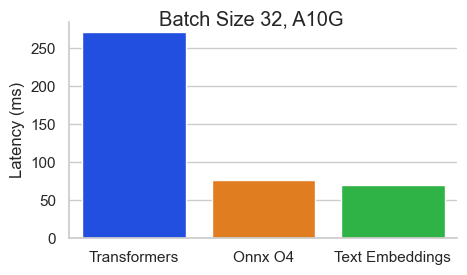
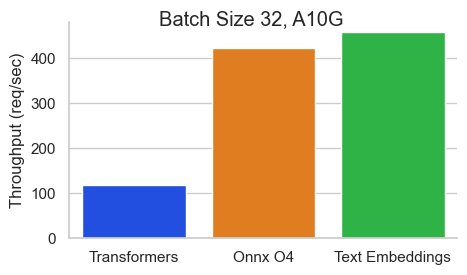
Benchmarks
Benchmark for BAAI/bge-base-en-v1.5 on an NVIDIA A10 with a sequence length of 512 tokens:
Getting Started:
To start using TEI, check the Quick Tour guide.