---
language:
- es
size_categories:
- n<1K
task_categories:
- summarization
pretty_name: Resumen Noticias Clickbait
dataset_info:
features:
- name: id
dtype: int64
- name: titular
dtype: string
- name: respuesta
dtype: string
- name: pregunta
dtype: string
- name: texto
dtype: string
- name: idioma
dtype: string
- name: periodo
dtype: string
- name: tarea
dtype: string
- name: registro
dtype: string
- name: dominio
dtype: string
- name: país_origen
dtype: string
splits:
- name: train
num_bytes: 5440051
num_examples: 700
- name: validation
num_bytes: 462364
num_examples: 50
- name: test
num_bytes: 782440
num_examples: 100
download_size: 3417692
dataset_size: 6684855
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
tags:
- summarization
- clickbait
- news
---

NoticIA: A Clickbait Article Summarization Dataset in Spanish.
We present NoticIA, a dataset consisting of 850 Spanish news articles featuring prominent clickbait headlines, each paired with high-quality, single-sentence generative summarizations written by humans.
- 📖 Dataset Card en Español: https://huggingface.co/datasets/somosnlp/NoticIA-it/blob/main/README_es.md
## Dataset Details
### Dataset Description
We define a clickbait article as one that seeks to attract the reader's attention through curiosity. For this purpose, the headline poses a question or an incomplete, sensationalist, exaggerated, or misleading statement. The answer to the question raised in the headline usually does not appear until the end of the article, preceded by a large amount of irrelevant content. The goal is for the user to enter the website through the headline and then scroll to the end of the article, viewing as much advertising as possible. Clickbait articles tend to be of low quality and provide no value to the reader beyond the initial curiosity. This phenomenon undermines public trust in news sources and negatively affects the advertising revenue of legitimate content creators, who could see their web traffic reduced.
We introduce NoticIA, a dataset consisting of 850 Spanish news articles with clickbait headlines, each paired with high-quality, single-sentence generative summaries written by humans. This task demands advanced skills in text comprehension and summarization, challenging the ability of models to infer and connect various pieces of information to satisfy the user's informational curiosity generated by the clickbait headline.
The project is inspired by the X/Twitter account [@ahorrandoclick1](https://x.com/ahorrandoclick1). [@ahorrandoclick1](https://x.com/ahorrandoclick1) has 300,000 followers, demonstrating the great value of summarizing clickbait news articles. However, creating these summaries manually is a labor-intensive task, and the number of clickbait news articles published greatly exceeds the number of summaries one person can perform. Therefore, there is a need for automatic summarization of clickbait news articles. Additionally, as mentioned earlier, this is an ideal task for analyzing the text comprehension capabilities of a language model in Spanish.
The following Figure illustrates examples of clickbait headlines from our dataset, together with the human-written summaries.

- **Curated by:** [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/), [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139)
- **Funded by:** SomosNLP, HuggingFace, Argilla, [HiTZ Zentroa](https://www.hitz.eus/)
- **Language(s) (NLP):** es-ES
- **License:** apache-2.0
- **Web Page:** [Github](https://github.com/ikergarcia1996/NoticIA)
### Dataset Sources
- **💻 Repository:** https://github.com/ikergarcia1996/NoticIA
- **📖 Paper:** [NoticIA: A Clickbait Article Summarization Dataset in Spanish](https://arxiv.org/abs/2404.07611)
- **🤖 Pre Trained Models** [https://huggingface.co/collections/Iker/noticia-and-clickbaitfighter-65fdb2f80c34d7c063d3e48e](https://huggingface.co/collections/Iker/noticia-and-clickbaitfighter-65fdb2f80c34d7c063d3e48e)
- **🔌 Demo:** https://huggingface.co/spaces/somosnlp/NoticIA-demo
- **▶️ Video presentation (Spanish):** https://youtu.be/xc60K_NzUgk?si=QMqk6OzQZfKP1EUS
- **🐱💻 Hackathon #Somos600M**: https://somosnlp.org/hackathon
## Uses
This dataset has been compiled for use in scientific research. Specifically, for use in the evaluation of language models in Spanish.
Commercial use of this dataset is subject to the licenses of each news and media outlet. If you want to make commercial use of the dataset you will need to have
the express permission of the media from which the news has been obtained.
### Direct Use
- 📈 Evaluation of Language Models in Spanish.
- 🤖 Instruction-Tuning of Spanish Language Models
- 📚 Develop new datasets on top of our data
- 🎓 Any other academic research purpose.
### Out-of-Scope Use
We expressly prohibit the use of these data for two use cases that we consider to be that may be harmful: The training of models that generate sensational headlines or clickbait, and the training of models that generate articles or news automatically.
## Dataset Structure
The dataset is ready to be used to evaluate language models. For this aim, we have developed a *prompt* that makes use of the news headline and text.
The prompt is as follows:
```python
def clickbait_prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Responde siempre que puedas parafraseando el texto original. "
f"Usa siempre las mínimas palabras posibles. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
```
The expected output of the model is the summary. Below is an example of how to evaluate `gemma-2b` in our dataset:
```
from transformers import pipeline
from datasets import load_dataset
generator = pipeline(model="google/gemma-2b-it",device_map="auto")
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
outputs = generator(dataset[0]["prompt"], return_full_text=False,max_length=4096)
print(outputs)
```
The dataset includes the following fields:
- **ID**: id of the example
- **Titular (headline)**: headline of the article
- **Respuesta (response)**: Summary written by a human being
- **Pregunta (question)**: Prompt ready to be used as input to a language model.
- **Texto (text)**: Text of the article, obtained from the HTML.
- **idioma (language)**: ISO code of the language. In the case of Spanish, it also includes the geographic variant ("Mexican Spanish" = es_mx, "Ecuadorian Spanish" = es_ec, ...).
- **Tarea (task)** Task of the example. Every example has the task `resumen` (`summary`)
- **Registro (Language Register)**: `coloquial`, `medio` o `culto` (`colloquial`, `medium` or `educated`)
- **Dominio (Domain)**: The domain (`prensa`, `press`) and the subdomain.
- **País de origen (Country of origin)**: Country of origin of the data.
*The Idioma (language), Registro (Language Register), Dominio (Domain) and País de origen (Country of origin) labels have been automatically generated using GPT3.5-Turbo.*
## Dataset Creation
### Curation Rationale
NoticIA offers an ideal scenario to test the ability of language models to understand Spanish texts. This task is complex, involving discerning the hidden question in a clickbait headline or identifying the information that the user is actually seeking. This challenge involves filtering large volumes of superfluous content to find and succinctly summarize the relevant information accurately.
In addition, by making our data and models public, we aim to exert pressure against the use of deceptive tactics by online news providers to increase advertising revenue,
### Source Data
#### Data Collection and Processing
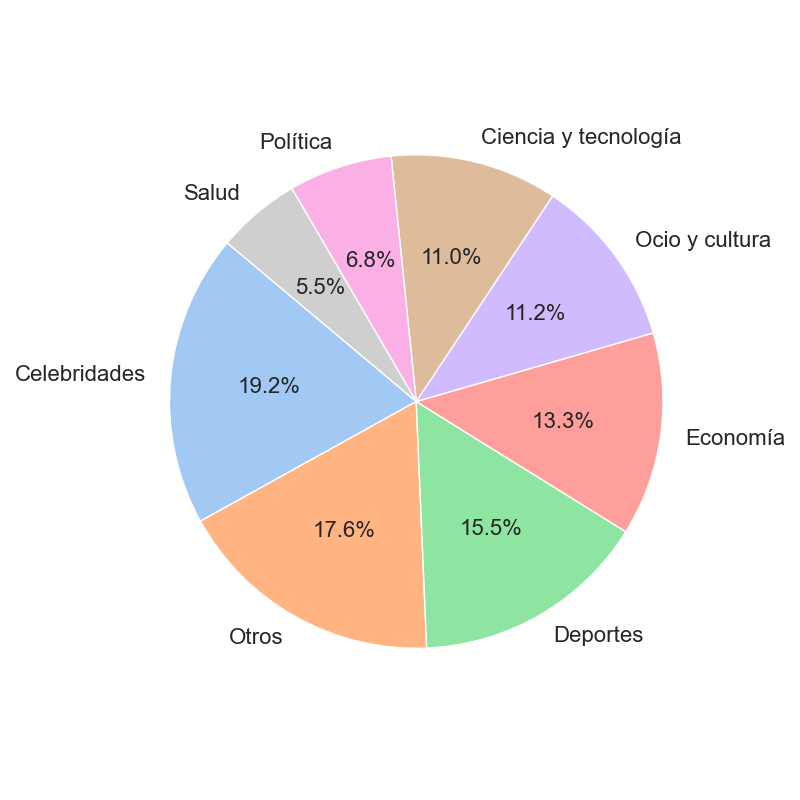
We have compiled clickbait news using the timeline of the X/Twitter user [@ahorrandoclick1](https://x.com/ahorrandoclick1). To do this, we extracted the URLs of the news mentioned by the user. Additionally, we have added about 100 clickbait news articles chosen by us. The following image shows the source of the news in the dataset.

We have classified each of the news articles based on the category to which they belong. As can be seen, our dataset includes a wide variety of categories.
#### Annotation process
Although [@ahorrandoclick1](https://x.com/ahorrandoclick1) provides summaries of clickbait news, these summaries do not follow any guidelines, and in many cases, their summaries do not refer to the text, but are rather of the style *"This is advertising"*, *"They still haven't realized that..."*. Therefore, we have manually generated the summaries for the 850 news articles. To do this, we have defined strict annotation guidelines, available at the following link: [https://huggingface.co/spaces/Iker/ClickbaitAnnotation/blob/main/guidelines.py](https://huggingface.co/spaces/Iker/ClickbaitAnnotation/blob/main/guidelines.py).
The dataset has been annotated by [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/) and [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139), and this process has taken approximately 40 hours.
### Dataset Statistics
We have divided the dataset into three splits, which facilitates the training of models. As can be seen in the following table, the summaries of the news are extremely concise.
They respond to the clickbait headline using the fewest words possible.
| | Train | Validation | Test | Total |
|--------------------|-------|------------|------|-------|
| Number of articles | 700 | 50 | 100 | 850 |
| Average number of words in headlines | 16 | 17 | 17 | 17 |
| Average number of words in news text | 544 | 663 | 549 | 552 |
| Average number of words in summaries | 12 | 11 | 11 | 12 |
[More Information Needed]
#### Who are the annotators?
- [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/): PhD Student HiTZ, the Basque center for language technology
- [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139): Postdoctoral research fellow at HiTZ, the Basque center for language technology
### Annotation Validation
To validate the dataset, the 100 summaries from the Test set were annotated by two annotators. This data is available here: https://huggingface.co/datasets/Iker/NoticIA_Human_Validation
The overall agreement between the annotators was high, as they provided exactly the same answer in 26% of the cases and provided responses that partially shared information in 48% of the cases (same response but with some variation in the words used).
This demonstrates that it was easy for humans to find the information referred to by the headline. We also identified a list of cases where the annotators provided different but equally valid responses, which accounts for 18% of the cases.
Lastly, we identified 8 cases of disagreement. In 3 cases, one of the annotators made an incorrect summary,
likely due to fatigue after annotating multiple examples. In the remaining 5 cases, the disagreement was due to contradictory information in the article and
different interpretations of this information. In these cases, determining the correct summary is subject to the reader's interpretation.
Regarding the evaluation of the guidelines, overall, they were not ambiguous, although the request to select the minimum number of words to generate a
valid summary is sometimes interpreted differently by the annotators: For example, the minimum length could be understood as focusing on the question in the headline or a minimum well-formed phrase.
# Massive Evaluation of Language Models
As is customary in summary tasks, we use the ROUGE scoring metric to automatically evaluate the summaries produced by models. Our main metric is ROUGE-1, which considers whole words as basic units. To calculate the ROUGE score, we lowercase both summaries and remove punctuation marks. In addition to the ROUGE score, we also consider the average length of the summaries. For our task, we aim for the summaries to be concise, an aspect that the ROUGE score does not evaluate. Therefore, when evaluating models, we consider both the ROUGE-1 score and the average length of the summaries. Our goal is to find a model that achieves the highest possible ROUGE score with the shortest possible summary length, balancing quality and brevity.
We have evaluated the best current instruction-following language models. We used the previously defined prompt. The prompt is converted into the specific chat template of each model.
The code to reproduce the results is available at the following link: [https://github.com/ikergarcia1996/NoticIA](https://github.com/ikergarcia1996/NoticIA)

## Bias, Risks, and Limitations
The dataset contains a small number of articles from Latin America; however, the vast majority of the articles are from Spanish news sources. Therefore, this dataset will evaluate the proficiency of language models in Spanish from Spain.
Although explicitly prohibited, a bad actor could use our data to train models that can generate clickbait articles automatically, contributing to polluting the internet with low-quality content. In any case, we consider the advantages of having a text comprehension dataset to evaluate language models in Spanish to be superior to the possible risks.
## License
We release our annotations under the Apache 2.0 license. However, commercial use of this dataset is subject to the licenses of each news and media outlet.
## Citation
If you use this dataset, please cite our paper: [NoticIA: A Clickbait Article Summarization Dataset in Spanish](https://arxiv.org/abs/2404.07611)
**BibTeX:**
```
@misc{garcíaferrero2024noticia,
title={NoticIA: A Clickbait Article Summarization Dataset in Spanish},
author={Iker García-Ferrero and Begoña Altuna},
year={2024},
eprint={2404.07611},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## More Information
This project was developed during the [Hackathon #Somos600M](https://somosnlp.org/hackathon) organized by SomosNLP. Demo endpoints were sponsored by HuggingFace.
**Team:**
- [Iker García-Ferrero](https://huggingface.co/Iker)
- [Begoña Altura](https://huggingface.co/baltuna)
**Contact**: {iker.garciaf,begona.altuna}@ehu.eus
This dataset was created by [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/) and [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139). We are researchers in NLP at the University of the Basque Country, within the [IXA](https://www.ixa.eus/) research group, and we are part of [HiTZ, the Basque Language Technology Center](https://www.hitz.eus/es).