人工智能水印技术入门:工具与技巧











近几个月来,我们看到了多起关于“深度伪造 (deepfakes)”或人工智能生成内容的新闻报道:从 泰勒·斯威夫特的图片、汤姆·汉克斯的视频 到 美国总统乔·拜登的录音。这些深度伪造内容被用于各种目的,如销售产品、未经授权操纵人物形象、钓鱼获取私人信息,甚至制作误导选民的虚假资料,它们在社交媒体平台的迅速传播,使其具有更广泛的影响力,从而可能造成持久的伤害。
在本篇博文中,我们将介绍 AI 生成内容加水印的方法,讨论其优缺点,并展示 Hugging Face Hub 上一些可用于添加/检测水印的工具。
什么是水印以及它是如何工作的?

水印是一种标记内容以传递额外信息(如内容的真实性)的方法。在 AI 生成的内容中,水印既可以是完全可见的(如图 1 所示),也可以是完全不可见的(如图 2 所示)。具体来说,在 AI 领域,水印指的是在数字内容(例如图片)中加入特定模式,用以标示内容的来源;这些模式之后可以被人类或通过算法识别。
AI 生成内容的水印主要有两种方法:第一种是在内容创作过程中加入,这需要访问模型本身,但因为它是生成过程的一部分,所以 更为稳固。第二种方法是在内容生成后应用,可以用于闭源和专有模型生成的内容,但可能不适用于所有类型的内容(如文本)。
数据投毒与签名技术
除了水印,还有几种相关技术可以限制未经同意的图像操纵。有些技术通过微妙地改变在线分享的图像来防止 AI 算法正确处理这些图像。尽管人类可以正常查看这些图像,但 AI 算法则无法访问类似内容,从而无法创建新图像。这类技术包括 Glaze 和 Photoguard。还有一些工具通过“投毒”图像来破坏 AI 算法训练中的固有假设,使得 AI 系统无法根据在线分享的图像学习人们的外貌——这让这些系统更难以生成假人物图像。这类工具包括 Nightshade 和 Fawkes。
通过使用“签名”技术,也可以维护内容的真实性和可靠性,这些技术将内容与其来源的元数据链接起来,如 Truepic 的工作,它嵌入了 遵循 C2PA 标准的元数据。图像签名有助于了解图像的来源。虽然元数据可以被编辑,但像 Truepic 这样的系统通过 1) 提供认证以确保可以验证元数据的有效性;以及 2) 与水印技术整合,使得删除信息更加困难,来克服这一限制。
开放与封闭的水印
为公众提供对水印器和检测器不同级别的访问权有其优点和缺点。开放性有助于促进创新,开发者可以在关键思想上进行迭代,创造出越来越好的系统。然而,这需要与防止恶意使用进行权衡。如果 AI 流程中的开放代码调用了水印器,去除水印步骤变得很简单。即使水印部分是封闭的,如果水印已知且水印代码开放,恶意行为者可能会阅读代码找到方法编辑生成的内容,使水印失效。如果还可以访问检测器,就可能继续编辑合成内容,直到检测器显示低置信度,从而无效化水印。存在一些直接解决这些问题的混合开放-封闭方法。例如,Truepic 的水印代码是封闭的,但他们提供了一个可以验证内容凭证的公共 JavaScript 库。IMATAG 的调用水印器代码是开放的,但实际的水印器和检测器是私有的。
对不同数据类型进行水印
虽然水印是跨多种模态(音频、图像、文本等)的重要工具,但每种模态都带来其独特的挑战和考量。水印的意图也不尽相同,无论是为了防止训练数据被用于训练模型、防止内容被操纵、标记模型的输出,还是检测 AI 生成的数据。在本节中,我们将探讨不同的数据模态、它们在水印方面的挑战,以及 Hugging Face Hub 上存在的用于实施不同类型水印的开源工具。
图像水印
可能最为人熟知的水印类型(无论是人类创作还是 AI 生成的内容)是对图像的水印。已经提出了不同的方法来标记训练数据,以影响基于它训练的模型的输出:这种“图像隐身”方法最著名的是 “Nightshade”,它对图像进行微小的修改,这些修改对人眼来说几乎不可察觉,但会影响基于被污染数据训练的模型的质量。Hub 上也有类似的图像隐身工具——例如,由开发 Nightshade 的相同实验室开发的 Fawkes,专门针对人物图像,目的是阻挠面部识别系统。同样,还有 Photoguard,旨在保护图像不被用于生成 AI 工具(例如,基于它们创建深度伪造)的操纵。
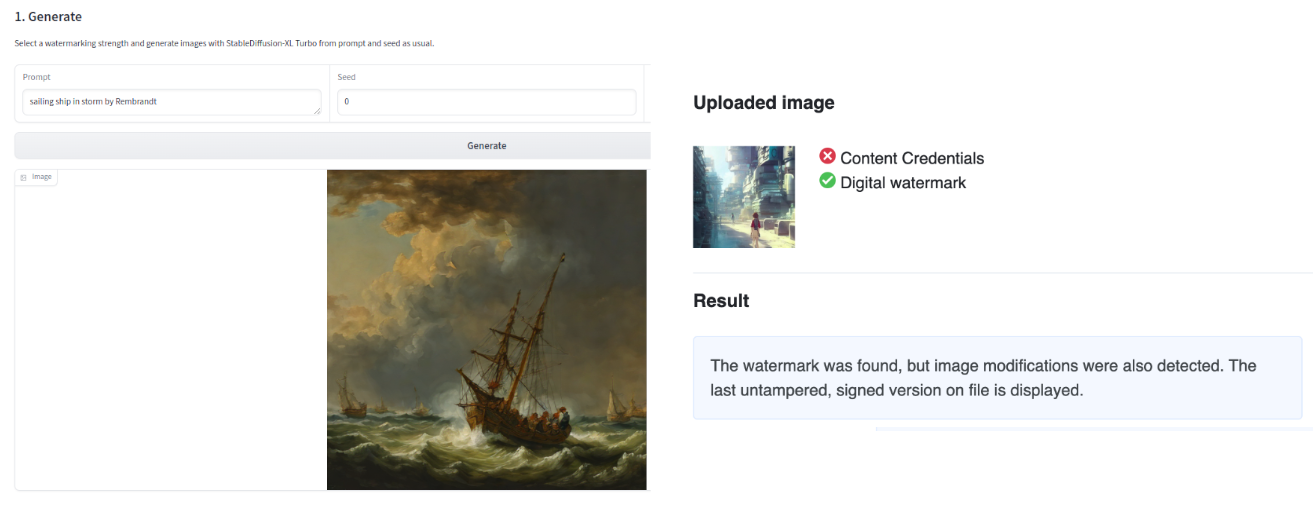
关于水印输出图像,Hub 上提供了两种互补的方法:IMATAG(见图 2),它通过利用修改过的流行模型(如 Stable Diffusion XL Turbo)在内容生成过程中实施水印;以及 Truepic,它在图像生成后添加不可见的内容凭证。
TruePic 还将 C2PA 内容凭证嵌入图像中,允许在图像本身中存储有关图像来源和生成的元数据。IMATAG 和 TruePic Spaces 还允许检测由它们系统水印的图像。这两种检测工具都是方法特定的。Hub 上已有一个现有的通用 深度伪造检测的 Space 应用 ,但根据我们的经验,这些解决方案的性能取决于图像的质量和使用的模型。
文本水印
虽然给 AI 生成的图像加水印似乎更直观——考虑到这种内容的强烈视觉特性——但文本是另一个完全不同的故事……你如何在文字和数字(令牌)中添加水印呢?当前的水印方法依赖于基于之前文本推广子词汇表。让我们深入了解这对于 LLM 生成的文本来说意味着什么。
在生成过程中,LLM 在执行采样或贪婪解码之前输出下一个令牌的 logits 列表。基于之前生成的文本,大多数方法将所有候选令牌分为两组——称它们为“红色”和“绿色”。“红色”令牌将被限制,而“绿色”组将被推广。这可以通过完全禁止红色组令牌(硬水印)或通过增加绿色组的概率(软水印)来实现。我们对原始概率的更改越多,我们的水印强度就越高。WaterBench 创建了一个基准数据集,以便在控制水印强度进行苹果与苹果的比较时,促进跨水印算法的性能比较。
检测工作通过确定每个令牌的“颜色”,然后计算输入文本来自于讨论的模型的概率。值得注意的是,较短的文本因为令牌较少,因此置信度较低。

你可以在 Hugging Face Hub 上轻松实现 LLM 的水印。LLM 水印 Space(见图 3)演示了这一点,使用了 LLM 水印方法 对模型如 OPT 和 Flan-T5 进行了应用。对于生产级工作负载,你可以使用我们的 文本生成推理工具包,它实现了相同的水印算法,并设置了 相应的参数,可以与最新模型一起使用!
与 AI 生成图像的通用水印类似,是否可以普遍水印文本尚未得到证明。诸如 GLTR 之类的方法旨在对任何可访问的语言模型(鉴于它们依赖于将生成文本的 logits 与不同模型的 logits 进行比较)都具有鲁棒性。在没有访问该模型(无论是因为它是闭源的还是因为你不知道哪个模型被用来生成文本)的情况下,检测给定文本是否使用语言模型生成目前是不可能的。
正如我们上面讨论的,检测生成文本的方法需要大量文本才能可靠。即使如此,检测器也可能有高误报率,错误地将人们写的文本标记为合成。实际上,OpenAI 在 2023 年因低准确率而悄悄关闭了他们的内部检测工具,这在教师用它来判断学生提交的作业是否使用 ChatGPT 生成时带来了 意想不到的后果。
音频水印
从个人声音中提取的数据(声纹)通常被用作生物安全认证机制来识别个体。虽然通常与 PIN 或密码等其他安全因素结合使用,但这种生物识别数据的泄露仍然存在风险,可以被用来获得访问权限,例如银行账户,鉴于许多银行使用声音识别技术通过电话验证客户。随着声音变得更容易用 AI 复制,我们也必须改进验证声音音频真实性的技术。水印音频内容类似于水印图像,因为它有一个多维输出空间,可以用来注入有关来源的元数据。在音频的情况下,水印通常在人耳无法察觉的频率上进行(低于约 20 或高于约 20,000 Hz),然后可以使用 AI 驱动的方法进行检测。
鉴于音频输出的高风险性质,水印音频内容是一个活跃的研究领域,过去几年提出了多种方法(例如,WaveFuzz,Venomave)。

AudioSeal 也被用于发布 SeamlessExpressive 和 SeamlessStreaming 演示,带有安全机制。
结论
面对虚假信息、被错误地指控生产合成内容,以及未经本人同意就使用其形象,都是既困难又耗时的问题;在可以进行更正和澄清之前,大部分损害已经造成。因此,作为我们使好的机器学习普惠化的使命的一部分,我们相信,拥有快速和系统地识别 AI 生成内容的机制是至关重要的。AI 水印虽不是万能的,但在对抗恶意和误导性 AI 使用方面,它是一个强有力的工具。
相关新闻报道
- It Doesn't End With Taylor Swift: How to Protect Against AI Deepfakes and Sexual Harassment | PopSugar (@meg)
- Three ways we can fight deepfake porn | MIT Technology Review (@sasha)
- Gun violence killed them. Now, their voices will lobby Congress to do more using AI | NPR (@irenesolaiman)
- Google DeepMind has launched a watermarking tool for AI-generated images | MIT Technology Review (@sasha)
- Invisible AI watermarks won’t stop bad actors. But they are a ‘really big deal’ for good ones | VentureBeat (@meg)
- A watermark for chatbots can expose text written by an AI | MIT Technology Review (@irenesolaiman)
- Hugging Face empowers users with deepfake detection tools | Mashable (@meg)

